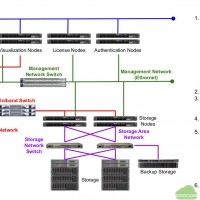
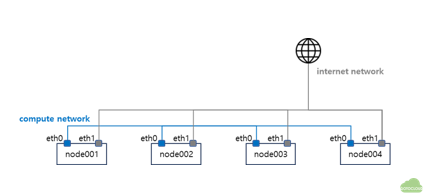
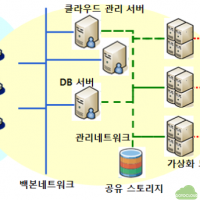
Typical HPC cluster architecture
For several decades after the vector supercomputers were replaced by the MPP (massively parallel processor) type supercomputers, the general architecture of high performance computing clusters consisted of compute nodes, high bandwidth and low latency interconnect network devices, and parallel file system based shared storage. Jobs were controlled by job schedulers such as LSF, PBS, and Slurm. Recently, some GUI nodes with high performance GPUs have been used for graphical pre- and post-processing.
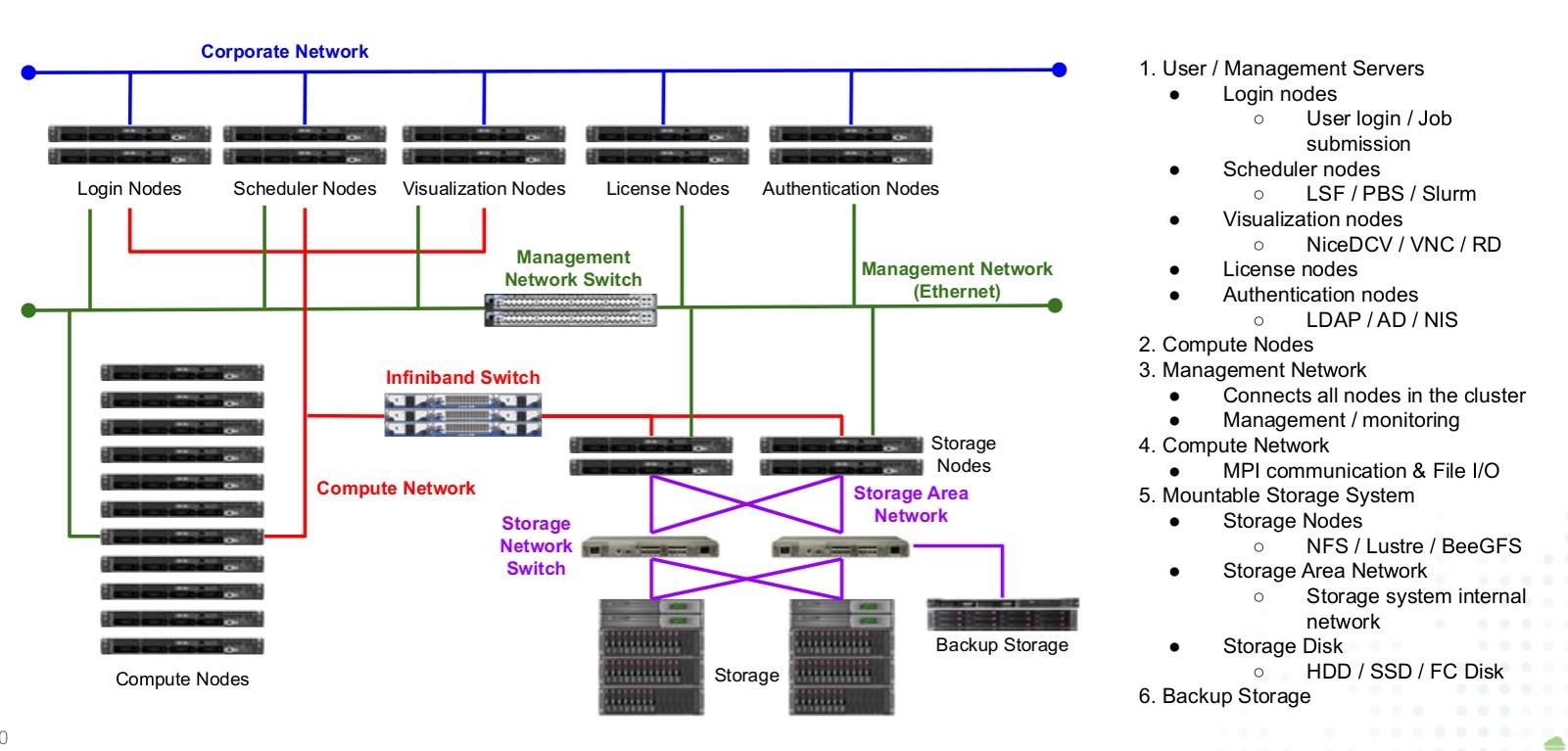
The diagram above shows the architecture of a typical HPC cluster. In this cluster, a user prepares simulation files, such as a mesh file, an executable program, and a script for the job submission, and transfers them to the HPC cluster using sftp or any other copy methods. Then, he/she logs in to a login node. After logging in, he/she submits a job to the scheduler. The job is queued and will start when the computational resource is available. After the job finishes, he/she can download the results or do the post-processing if the visualization nodes are available. This process is the typical work process in the HPC cluster until now.
Change of simulation workflow
With the performance improvement of desktop and workstation, the GUI-based interactive simulation applications such as MATLAB, ANSYS Workbench, Siemens Simcenter, the spread of IDE (Integrated Development Environment), and various other developments in the IT field including HPC cloud, there is an increasing demand for using these IT-based environments seamlessly in the HPC field. To keep up with this trend, Ansys has launched Ansys Cloud Direct, which allows users to run large-scale analysis tasks directly on cloud environments such as AWS, in addition to the RSM (Remote Solver Manager), which allows users to run simulation tasks on HPC from the existing Interactive GUI. Siemens also provides Simcenter Cloud HPC, which allows users to run HPC tasks on the cloud directly from the local client.
The State of Data Science 2021 which is a report by Anaconda that surveyed over 4,500 data science practitioners and enthusiasts from 130 countries provides insights into the trends, tools, and challenges of data science in 2021. According to the report, Jupyter Notebook is the most popular IDE for data science, used by 64% of the respondents, followed by Visual Studio Code (39%), PyCharm (36%), and Spyder (29%). But the Vim editor is used by only 7% of the respondents.
Next generation supercomputer architecture
Jupyter Scheduler, which is being developed to enable users to run Jupyter notebooks on from local computer to cloud, on-premise HPC cluster, JupyterHub, any supercomputer can be seen as an example that reflects this concept well. Similarly, various supercomputer applications should also be designed with an architecture that includes middleware that allows users to run them on the desired infrastructure, from local computer to cloud, on-premise HPC, or exascale supercomputer, at the desired time. Along with this, storage architecture that can minimize data movement should also be considered.
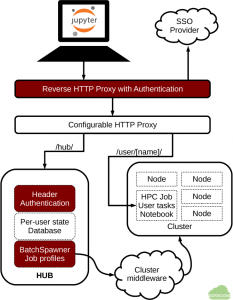
Jupyter as Common Technology Platform for Interactive HPC Services | DeepAI
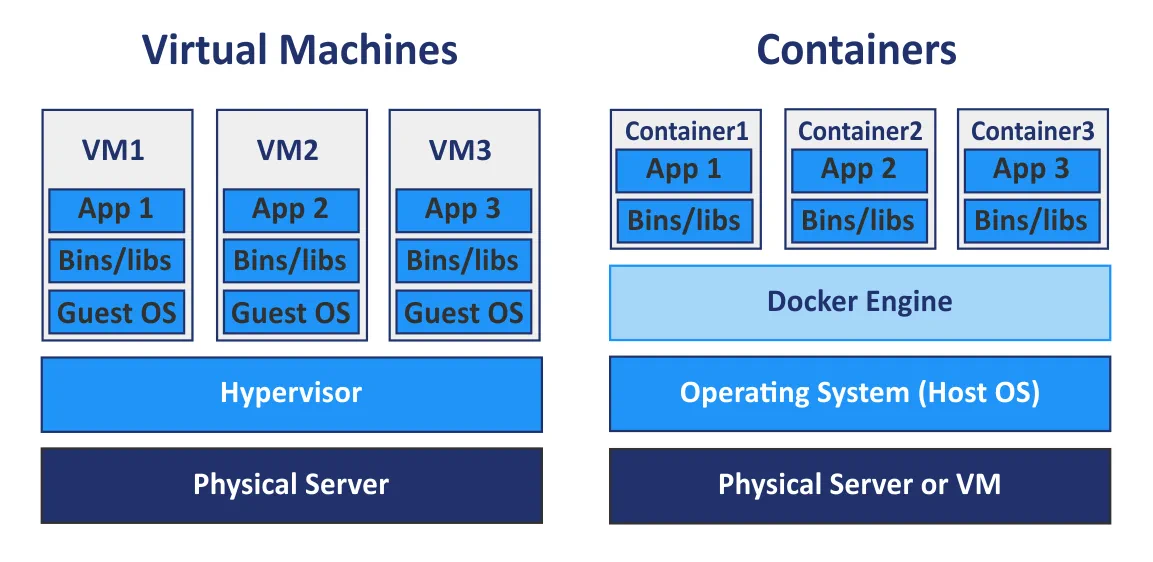
{kind=link}